In my last blog post I discussed the different definitions and features of thesauri. Now, I will turn to the next kind of knowledge organization system in the spectrum of complexity: ontologies.
Actually, to consider an ontology as a more (or most) complex type of controlled vocabulary or knowledge organization system, after thesauri, due to additional features, is just one perspective or definition of ontologies, which is not universally shared.
When I first learned about ontologies, coming from my
taxonomist perspective, I considered ontologies as merely a more complex type
of taxonomy or thesaurus, characterized by customized semantic relationships
between concepts (rather than merely hierarchical or associative relationships),
more expressive attributes for concepts (rather than mere scope notes), and the
grouping of concepts into classes to manage the semantic relationships and attribute
types. In fact, I wrote in 2008 for the first edition of my book “An ontology
can be considered a type of taxonomy with even more complex relationships than
in a thesaurus,” which the following graphic represents.

As my understanding has evolved, I would consider this just to be one kind of understanding or definition of ontology among others. In other words, a controlled vocabulary that has the features of semantic relationships, classes of concepts, and attributes for concepts, can be considered a kind of ontology, but there are other definitions and understanding of ontology within the field of information/knowledge management.
While we usually refer to “controlled vocabularies” as the over-arching category for these things, it is probably better to go up a further level and call an ontology a kind of “knowledge organization system,” rather than a kind of controlled vocabulary. Controlled vocabularies are kinds of knowledge organization systems, where the emphasis is on managed terms or concepts for the purpose of tagging or categorizing and information retrieval. Ontologies, by themselves, are not necessarily for information retrieval, at least not directly. And this is one of the points of differing definitions of ontologies.
Differing definitions and perspective
There are differing definitions of the word ontology: (1) branch of philosophy that studies existence, being, becoming, and reality (Wikipedia: Ontology), and (2) a representation, formal naming, and definition of categories, entities, properties, and relations within a domain (Wikipedia: Ontology (information science)). Of course, we are interested in the second definition, although there are some connections between the two.
The second definition, however, is already multidisciplinary, as it is a concept shared in both information science and computer science. Information scientists (including librarians, taxonomists, and knowledge managers) and computer scientists do not have different definitions of ontologies, but rather different approaches to and perspectives of ontologies and different purposes for the ontologies they create. For computer scientists, modeling data and information helps them design a computer program to perform desired functions. For information scientists, modeling data and information makes it easier to retrieve information with complex queries. Information scientists consider an ontology as a kind of knowledge organization system, whereas computer scientists tend to consider an ontology as a form of knowledge representation.
Yet even among information scientists, who consider ontologies as knowledge organization systems and have the same objectives in developing ontologies, there are different understandings of what exactly constitutes an ontology and how it relates to other knowledge organization systems, such as taxonomies. This is due to (1) different emphasis on various ontology components, (2) the question of adherence to ontology standards, and (3) the way different ontology software tools model ontologies and their relations to taxonomies differently.
Differing understandings of ontology components
There is a shared understanding that ontologies are composed of things, their properties/attributes, and their relationships.
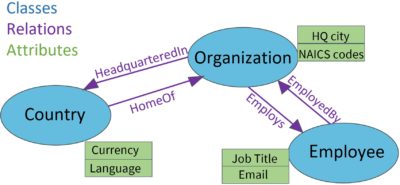
However, there are differences in understand of the two kinds of things: classes and individuals. Classes are categories or groups of things with shared characteristics, whereas individuals are specific instances of things. This seems obvious, but if you approach ontology design from the perspective of taxonomy design it can become less certain. Is an individual the most specific concept (also called “leaf node”) in a hierarchy, or is an individual a named entity/proper noun? The definition of components of ontologies does not answer this question, because ontology structures are meant to model data, not to organize taxonomy concepts that could be either generic (common nouns) named entities (proper nouns). Drawing the line between classes and individuals can be challenging, but whether this matters may depend on what tool you are using.
Furthermore, ontologies may have other components, such as axioms, rules, restrictions, events, and function terms, but ontologies as knowledge organization systems rarely have all of these.
Differing ontology standards or languages
In 2004 the World Wide Web Consortium (W3C) published the Web Ontology Language (OWL) specification, which is based on the Resource Description Framework (RDF), as “ a Semantic Web language designed to represent rich and complex knowledge about things, groups of things, and relations between things,” which has become widely adopted. Now it is common to think that ontologies must follow OWL guidelines. But (information science) ontologies have existed before OWL, and an ontology does not have to follow OWL to be called an ontology. There are other ontology languages besides OWL, but they are not as common. To share and reuse ontologies, it is recommended to follow the OWL standard.
Differing ontology modeling software
While one could design the high-level model of an ontology in a mind-mapping tool, there would be no enforcement of standards or best practices (preventing duplications or incomplete data, etc.), and it’s difficult to scale, so dedicated ontology modeling software is recommended. However, ontology modeling/editing software does not model ontologies all in the same way.
The main difference is probably between stand-alone ontology software (such as Protégé or TopBraid Composer) and software that combines ontology with taxonomy/thesaurus development and editing (such as PoolParty, Semaphore, or Graphite). Stand-alone ontology editing software supports creating a detailed ontology as single model, thus including classes, multiple levels of subclasses, and individuals (instance concepts). In integrated software that combines taxonomy/thesaurus development with ontology development, the taxonomy or thesaurus (or multiple controlled vocabularies) is created in one space with one set of software features, and the ontology is created in another space with a different set of features. The ontology (or even just parts of it) is then applied to the taxonomy, so that concepts in the taxonomy inherit the attribute types and relationships of their associated class, and the taxonomy concepts are like individuals in the ontology. The ontology can be considered a semantic layer in the model, as the following graphic illustrates.

These two different approaches to ontology modeling thus result in different definitions of an ontology. A ontology is likely to be considered as a more complex type of knowledge organization system by users of stand-alone ontology software, whereas an ontology is likely to be considered and expressive semantic layer applied to one more taxonomies by users of integrated taxonomy/ontology software.
Ontology lite or ontology-like
When I was still considering ontologies more akin to thesauri with semantic relationships, and I expressed such views in a discussion forum, someone (whom I don’t remember), referred to this kind of ontology as “ontology lite,” since it has features of an ontology, but does not fully follow an ontology model and standards. This is not necessarily a bad thing. Controlled vocabularies and knowledge organization systems can be considered along a continuum, and you should build what works for your situation.
Another kind of ontology-like structure is when you start linking multiple controlled vocabularies together. My initial experience with working on commercially implemented ontologies had been with such ontology-like systems, which were not actually called ontologies, at a former employer Gale. There we had controlled vocabularies (also called object classes) for subjects, persons, places events, products, companies/organizations, named works, etc., many of which had customized reciprocal relationship pairs between them (such as the relationship pair Creator/Creatby, between person names who were authors, and named works) and many customized term attributes (such as Birthdate, Death date, Birth city/state/country, Death city, state/country for persons).
I also heard this approach recently from a speaker, Ahren Lehnart, at Taxonomy Boot Camp conference, who described the linking of controlled vocabularies with related match (not equivalent match) relationships as “trending toward” creating an ontology.